Checking the spell checker
Have you checked out the Google wave video? Isn’t it just amazing. The endless possibilities, right? Frankly, the collaborative editing tools were nice, but what really amazed me was the spell checker, and the char-by-char chatting mechanism. The amount of time I spend staring at the screen - ”**** is typing”. Ugh! Maybe this feature will be added to gTalk soon? Personally, I’m hoping Facebook developers will look into it, and improve their chatting mechanism or maybe they could just get their existing chatting mechanism to work flawlessly. Any of the options would make me happy. ;-)
The spell checker was a “Context based spell checker.” Just amazing! If any spell checker can automatically convert “Icland is an icland” into “Iceland is an island” then it’s freaking amazing!
But, then I went and tested it out myself. It didn’t seem that great. For one - it was kinda slow, and the “Icland is an icland” example didn’t really work. What did work was “It’s bean a long time”. Maybe it just needs some work. Wave is currently in the beta testing phase.
Anyway, the spell checker really got me thinking - Why hasn’t it been done before? How hard could it be? It turns out English is an insanely difficult language. They are formal rules, but all of them, ALL of them, have exceptions. Still, somehow most of us have no problem speaking and reading it. And if we read a sentence like “I eat some cake yesterday”, we know it’s incorrect. (In case you didn’t spot the error. “eat” should be “ate”)
The current model of spell checker consists broadly of two parts -
- A routine for extracting words from the text.
- An algorithm for comparing the extracted words against a known list of correctly spelled words (Dictionary)
The routine for extracting words, in English, isn’t that hard. For languages like Chinese, it is a lot tougher. The main part is the comparing algorithm. Which isn’t that simple, but is doable. GNU aspell is one example. The problem with this kind of approach is that while is guarantees spelling correctness. That doesn’t necessarily mean that the statement will make sense. A classical example is “Where have you bean?“. It’s correct according to the dictionary, but we know “bean” is an object. The correct word should have been, “been”.
Google’s method is based on what they like to call “Large Statistical Language Models”. To summarize - they have combined their search engine and a spell checker. This is something most of us do all the time.
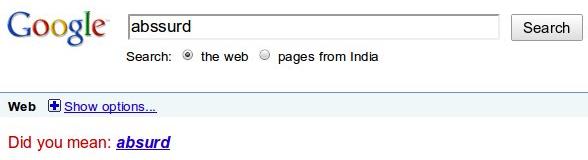
Their Natural Language Processing Video gave me the impression that it is somewhat computationally expensive, though I’m sure I’m blatantly wrong about this. Their spelling engine apparently takes its roots from Google Translator. I really don’t know how to look at it. On one hand, the concept is amazing, but then if I spell checker can’t correct a simple ‘ot’ into a ‘to’ or even suggest it in its options. But then it is, as I said earlier, in the beta testing phase.
All this info, unleashed my geek side, and I’ve decided to write my own spell checker, using existing technologies. Open source rocks! I though I’ll use existing Natural Language Processing technologies to parse every sentence and then apply a “Parts of speech Identification algorithm” on it. Then use basic rules to check the sentence for correction. For example - English is a Subject Verb Object language. So, maybe I could check if the subject and object both are in plural/singular. Simple stuff. Maybe.
I’ll post in a couple of days to update you on how miserably I’ve failed (or succeeded.) Wish me luck.