Text Splitting and Indexing
Over the last week, we have been working on improving the file searching experience in Plasma. We were mostly doing a decent job, but we were lacking in terms of proper Unicode support and making it simpler to search in non English languages. This blog post is a simplified explanation about now what goes on internally.
For the purpose of this discussion, I’m going to treat all files as blobs of text.
How indexing works?
When we’re indexing a file we typically have to take all the text and split it into words. This process is called Text Segmentation or Tokenization.
The most trivial implementation of this is just splitting on any white space. However, in practice it gets way more complex as punctuations need to be taken into account. Fortunately, there is an existing standard for this.
After obtaining the words one needs to simplify the words. Since Plasma is not dependent on one language when we do this, we need to do it in a language independent manner.
Currently we do the following -
-
Strip all diacritic marks. So words such as ‘mañana’ become ‘manana’.
-
Simplify all the characters. The moment you move away from the simple english characters, stuff gets complex. The same word can be represented in multiple ways in memory. For example the letter
ñcan be written asñor asn + ◌̃. We want to consume the minimum number of characters to represent it.
Finally, we’re ready to store the words. We generally store them in a big table where every word corresponds to the file it was found in.
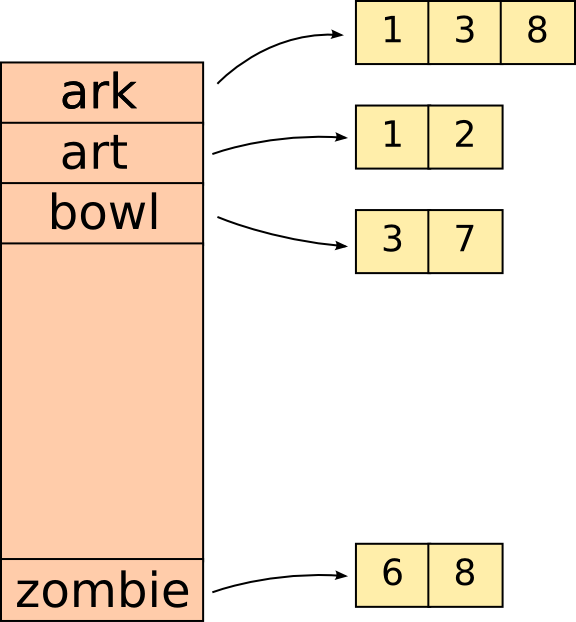
Here each file is represented by a number in order to save space.
We additionally also store where in the file every word was found. This comes at an expensive cost as with Xapian storing positional information doubles your database size. This means slower indexing and more IO consumption.
How searching works?
The initial part of search process is quite similar to the indexing process. When we get a string to search for, we split it up into words, and then simplify each word in the exact fashion we did when indexing those words.
After this we simply lookup each of the words in the table and return the set of files which matched every word.
For example if we were searching for the words árk Zombie in the above table. It would look as follows.
ark AND zombie -> (1, 3, 8) AND (6, 8) -> 8.
Phrases
The explanation above works for simple words, but the moment you bring in more complex words, stuff starts to get a little messy.
Imagine searching for an email address vhanda@kde.org. This would be split into 3 words vhanda, kde and org We could just search for these 3 words, but that’s not exactly what the user expected. They expect these words to appear in that exact order. This is where the positional information that we stored during indexing is used. We now search for those 3 words but we make sure they appear consecutively.
This does give some minor false positives such as a document containing the text “vhanda kde org”. But in general, it gives us what we want. It also allows users to explicitly search for words appearing consecutively.
Filtering vs Searching
Searching on the Desktop is quite different than searching on the web. Not only are we expected to be much faster, the wealth of information available is much smaller. This results in users expecting searches to work as a filter.
When searching on the web, one generally types the full word. On the desktop, however, depending on the feedback one will only type a part fo the word.
Example: Say searching for a file with the name Dominion - The Flood. One can expect the user to start typing Dom see many other results pop up and then type flood in order to get the desired file. They might never actually type the full word dominion.
Searching by typing only parts of the word gets more complex from an implementation point of view. We only have a mapping from (word) -> (file). So in order to search for a part of the word, we need to iterate over the table and look for every word which starts with that prefix. This makes the query quite long.
Example: Searching for Fi rol might expand to (fi OR fight OR fill finger OR fire) AND (rol OR role OR roller OR rollex)
This whole method of expanding the prefix to every word breaks down when the word is extremely small. Depending on your index expanding one word could result in over 10000 words. Practically, it results in results much much larger than 10000, and that makes the query slower and consumes a crazy amount of memory to represent the query. In these cases we typically try to guess which words occur more frequently than others and only expand the word to the most frequently occurring words.
So, what’s changed?
With Plasma 5.1, we’ve moved away from using Xapian’s internal Query Parser and word segmentation engine. We’re using our own custom implementation in Qt.
This gives us more control over the entire process, it makes it more testable as we have unit tests for every condition, and lets us modify it in custom ways such as splitting on _, removing diacritic marks and expanding every word when searching for queries.