What's new with Nepomuk 4.10
I’ve blogged about some of the more prominent changes in this new Nepomuk release. I thought it would be a good idea to document all the changes, which Nepomuk has gone through thanks to Blue Systems!

File Indexing
As the release announcement has been saying, the file indexer has undergone the maximum number of changes.
New Double Queue Architecture
We’ve split the working of the indexer into two parts - The first basic indexing and second full file indexing. The basic indexing quickly indexes the basic information about the file such as the filename and mimetype. This allows us to always at least answer simple queries. The other queue, which is only run when the user is idle, extracts the full information about the file.
New File Indexer
We’ve had some problems with Strigi earlier. With 4.10, we have finally decided to release our own solution. Our solution is arguably technologically inferior, but it’s more maintainable and, for now, provides a better user experience.
Mimetype Filtering
One of the advantages of moving to this new file indexing architecture is that mimetypes are a very important part. All of the file indexing plugins use mimetypes to identify which types of files they can index. With this, we decided to allow the user to control the type of files that are indexed.
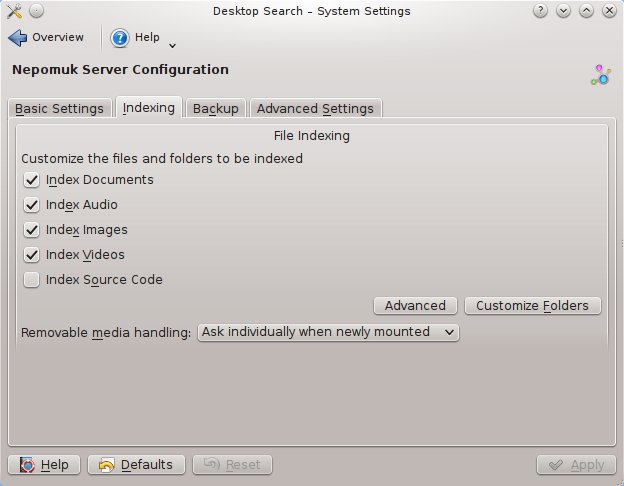
By default, source code is now no longer indexed. Common stuff like Documents, Images, Audio and Videos are.
KioSlave changes
Till the 4.9 release, the kioslave code hadn’t changed much. With 4.9.1, we managed to optimize some of the code. The 4.10 release however takes this to an entirely different level.
Massive Optimizations
The ‘nepomuksearch’ tagging slave could initially show both non-file and file data. This means that it would also occasionally show contacts, albums and other details. Selecting any of those would result in another search for resources related to that contact. For this release, we decided to optimize for the most common use case of listing files.
The ‘nepomuksearch’ kioslave, and all other nepomuk kioslaves, now no longer show any result which does not have a URL. This coupled with a LOT of other optimizations, has now yielded a super fast kioslave which can display thousands of results in under a second.
There is also some interesting userbase documentation about custom queries on the nepomuksearch kioslave.