Shared Memory Hash Table
For the last month I’ve been working on a hash table which is stored in shared memory and can thus easily be used across applications. This is ideal for simple caches of data that reside in multiple applications. My specific use case was the Nepomuk Resource class, which is a glorified cache of key value pairs and uses a hash table. A considerable amount of effort has gone into making sure that each application’s Resource classes are consistent with the other applications.
I always thought something this basic would have been implemented, but I just couldn’t find a shared memory hash table which actually supported resizing.
Basic Hash Table
Hashing is arguably one of the most important concepts of computer science. If you aren’t aware of how it works here are some nice links -
Shared Memory Hash Table
When implementing a hash table in shared memory, one encounters a couple of problems which normal hash tables do not have to deal with. Namely ‘named memory locations’. In the Unix world each shared memory location has to be given a unique identifier so that it can be accessed by other applications. Because of that we cannot allocate each Node/Bucket independently.
Most hash tables, which handle collisions by chaining look like this
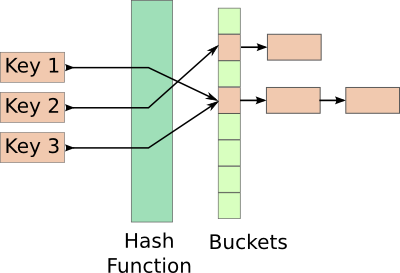
Allocating a new named shared memory region for each node seems like quite an overkill.
Structure
Since everything has to fit inside a contiguous memory location, we need to structure the hash table a little differently.
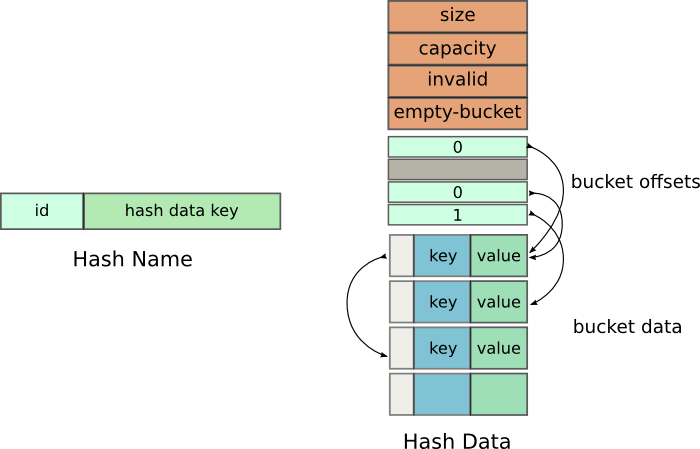
We use two shared memory locations - HashName and HashData. This is
done cause a hash table is not fixed in size, and will need to be
reallocated. With the reallocations, a new named shared memory will have
to be created, and all existing clients would need to be informed to use
this newly allocated location which would have a different name.
Instead we use HashName as the unique identifier the client knows
about, and HashData is internally used and can be changed when the
hash table needs to grow in size.
Hash Name data

The additional integer is a micro optimization. Whenever a client needs
to use the hash table they need to make sure that they are connected to
the appropriate shared memory, and not the old version. The code does
that by checking if HashData name is the same as the same as the one
provided by HashName.
This results in a string comparison, which would take a certain number of cycles depending on the length of the string. We use an additional integer to indicate the if the string has changed. Integer comparisons are a lot faster than string comparisons.
Internal Data
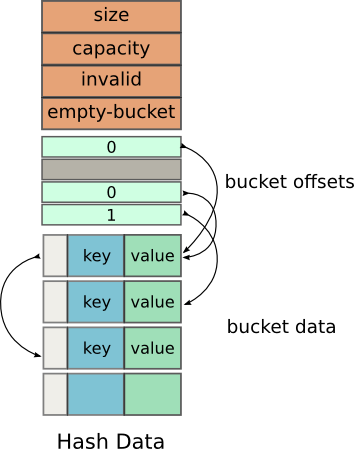
Most of the initial members are quite obvious, but I’m still listing them.
Size: The number of elements in the hash table
Capacity: The total number of elements the hash table can hold
Invalid: The number of buckets that invalid (have been deleted)
Empty-Bucket: The offset of the next empty bucket which may be used for insertion
After this comes the array of offsets referred internally as m_buckets. This array instead of holding the pointers to the Buckets, like in a traditional hash table, it holds offsets from the beginning of the next array.
The next array is an array of Bucket s, which is internally referred to as m_data. This array holds the key value pairs. A typical Bucket is defined as -
struct Bucket {
KeyType key;
ValueType value;
int hash;
int link;
}The link member is again not a pointer, but it contains the integer
offset to the next Bucket from the start of m_data.
Insertions
Insert operations are quite simple. The key is hashed into an integer,
which after a modulo operation is used as the index.
The corresponding index is checked in m_buckets. If m_buckets does
not already have some value over there, there is no collision and we
just allocate a new Bucket and plug in its offset.
Allocations of new buckets are done by consuming the location given by
emptyBucket, and then incrementing its value.
If m_buckets does not have an empty value, we go to the corresponding
Bucket, and follow its link until the link is empty. At that point we
allocate a new node and make the link point to this new Bucket. This
approach is almost identical to that of conventional chaining, except
that we are using offsets instead of pointers.
Deletions
Delete operations are fairly similar to insertions. The index is procured by hashing they key, and performing a modulo operation with the capacity. After which m_buckets is used to get the offset of the actual Bucket. Instead of deleting the bucket, which would not be possible cause it is stored in an array, we simply mark it as invalid.
The number of invalid buckets is then updated, and m_buckets[index] is marked as empty. Later during the resize operation, the wasted memory will be cleaned up.
Note: Deletions are actually a little more complex because of collisions, but you just need to traverse the entire link chain, and mark the corresponding Bucket as invalid
Resizing
The resize operation occurs when the loadRatio of the hash table goes above a certain threshold. For now, I’ve set it to 0.8.
loadRatio = (invalid-buckets + size) / capacity
When the loadRatio goes above 0.8, a new shared memory location is
allocated. The metadata (size, capacity, invalid and empty-Bucket) are
initially copied to the new shared memory. After which the offset for
each bucket is recalculated ( hash % newCapacity ), and it is inserted
into the new shared memory.
The invalid buckets are ignored and they are not copied.
Once the copying is completed, the hash data key in HashName is
updated, the id is incremented. This is done so that all other
applications using the shared memory can update their internal pointers.
Iterating
Iterating over the hash table is probably the only operation that is a
lot simpler than traditional hash tables. We already have all the data
listed as an array - m_data. All we need to do is iterate over it
while discarding invalid buckets which were created by delete
operations.
Well, in theory.
In practice, safely iterating over a shared hash involves copying the element being accessed. Mainly because another application could have shrunk the entire memory and your index could no longer be valid.
Another possible way is to copy its contents to a QHash. I’ve
implemented a simple function for that.
Problems
Dynamically allocated Types
You cannot use any types which dynamically allocate memory as the key
or value. This rules out QString, QUrl, QVariant (kinda) and
most of the commonly used Qt Data Structures. If you need to use a
string as the key, you’ll need to explicitly set an upper limit by using
something like QVarLengthArray.
This is a huge problem, and makes using the shared hash very difficult in practice.
Source Code
All of the code is currently lying in my scratch repository - kde:scratch/vhanda/sharedhash